理解URL锚点在HTML中的定位技术原理
一、锚点是什么
锚点就等同于火影中的“飞雷神之术”,我们先看百科中锚点的解释:
使用命名锚记可以在文档中设置标记,这些标记通常放在文档的特定主题处或顶部。然后可以创建到这些命名锚记的链接,这些链接可快速将访问者带到指定位置。
创建到命名锚记的链接的过程分为两步。首先,创建命名锚记,然后创建到该命名锚记的链接。
再看看“飞雷神之术”的解释:
日本动漫《火影忍者》中时空术的一种,S级。利用标记完成空间穿梭。

都是做标记,然后快速定位。说不定AB(岸本齐史)也是个网页制作爱好者哦!
其实,关于锚点,我3年前就写过一篇针对性文章:“关于锚点跳转及jQuery下相关操作与插件”,不过内容略浮躁,都是偏表象、偏基本应用层面的东西;这里还是关于锚点,探讨的内容可能更深层次一点。
其实web页面上还有一种定位,称为“focus定位”,也称“聚焦定位”,当页面上控件,例如文本框、单复选框、按钮等在『可响应聚焦状态①』下,通过类似label for或JS ele.focus()触发焦点选中状态的时候,也会发生定位②。这个以后有机会探讨,这里,专注锚点定位。
//zxx: ① 非
disabled状态,同时没有应用visibility:hidden以及display:none等CSS声明。其中,单纯应用pointer-events:none的控件元素是可以被focus的,pointer-events:none的作用更多类似完全穿透,而非不可用。② 我只在Chrome浏览器下做过完整测试,至于IE6这些奇葩,按照以往经验,也应如此。但IE6的尿性大家都尝过的,我不100%保证,大家自备照妖镜。
二、web网页中锚点定位的触发
当下,锚点定位的应用一般有:href="#"返回顶部;或者文章较长时候的标题索引,类似下面: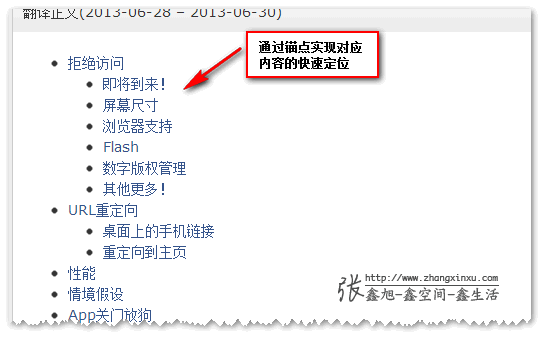
这类应用往往都是通过点击触发的,于是,难免的,我们可能就很简单地认为锚点定位的触发是通过点击事件。
而实际上,这种顺势而然的理解类似于古人理解为太阳绕着地球转一样,是有失偏颇的。
我个人认为,锚点的定位是通过浏览器URL地址的hash触发的。
hash?
CSSer们可能对hash这个名词不感冒,hash中文一般翻译为“哈希”,为方便记忆,你也可以读作“拉稀”。Hash是程序中非常重要以及常见的概念,可以实现内容的快速查找,这一点跟锚点很类似。
JS中,并没有专门的hash的说法(虽然object干了类似的活)。但是,有一个地方,确是实打实、正儿八经出现了hash!这就是location.hash.
例如,某页面的URL是:
http://this.summer.io/is/#hot // location.hash → #hot
则,location.hash值就是#hot.
这里#hot再URL地址中是有个专有名词的,叫什么来着? 协议?主机?域名?路径?擦,显然都不对!罢了,大家就叫“哈希”吧;恩,似乎太生僻了,那叫“拉稀”吧;额,好像又难听了点,就叫“锚链”吧。
画性大发,画个抽象派的图吧。
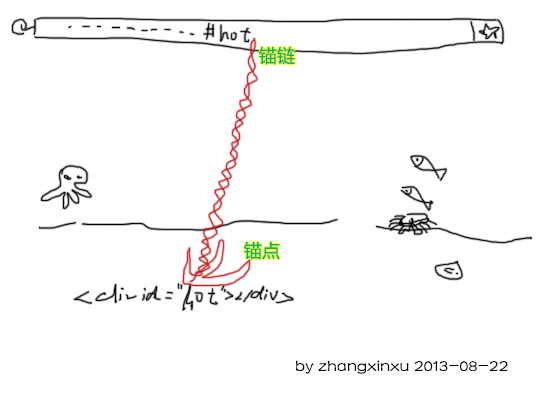
上图很抽象地暴露了锚链和锚点的基友关系。也就是说,页面之所以能定位到锚点所在位置,都是因为URL地址中的锚链的作用,而不是点击行为。最好的证据就是,当重新载入带有锚链的页面时,锚点依然会被定位。
了解锚点定位的触发源有助于我们实际应用时候问题的规避等处理。
三、web锚点定位的机制
帷幕渐渐拉来,高潮慢慢到来。
作为页面制作开发人员,锚点定位一定都有用过④。然,就跟打飞机一样,大家都会打,也打得来;但是,可能就没想过这飞机运动的机制什么,我是不是从中发现什么,然后开个挂,秒了众多好友。我想,锚点定位可能也是如此。今天,我就说说我对锚点定位机制的理解。
//zxx: ④ 如果你睁大懵懂的双眼,楚楚可怜的看着我说,“主啊,我没用过锚点定位诶”;那么,我请你,去超市买包“炫迈口香糖”,一遍嚼炫迈口香糖,一边点击本页面右下角的返回顶部,直到没有味道,或者页面URL地址后面出现#为止。
1. 锚点定位他丫就是滚床单
锚点定位的机制就是滚床单!
不要邪恶,这里的滚床单就是滚床单,比方说下面的这位狗兄:
床单即页面中可滚动的元素,汪星人则是该元素内部的的锚点元素,锚点定位就是汪星人滚床单。噢啦!
OK,注意这里的两个重要条件:
❶. 元素可滚动;
❷. 锚点元素在内部;
换句话就是无滚动则无定位!此话务必牢记。
举个普通的板栗:
夏天很热,因为妹子们衣服穿的少,如下HTML:
<img id="hot" src="http://image.zhangxinxu.com/image/study/s/s512/mm1.jpg">
于是,当含有#hot地址的时候,妹子图片就会顶着浏览器窗口上边缘显示了(如果滚动距离足够,比方说1920宽的显示器只能滚动一点)。
您可以狠狠地点击这里:夏天很热,因为妹子穿的少demo

之所以美女图片会浏览器窗口顶端显示,是因为其父元素存在滚动条,可以滚动。
锚点定位的本质就是修改容器的滚动高度;如果父容器无滚动,则锚点定位就是失效的命,再举个有滚动条但不滚动的例子。
您可以狠狠地点击这里:父容器无滚动锚点定位失效demo
美女图片的id是hot, 如下截图(img#hot…):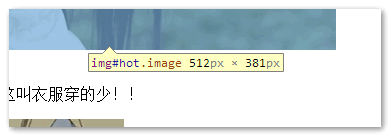
URL锚链也是#hot, 但是,美女却没有被锚上去,而是,傻傻地看着你,看着你……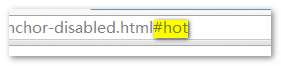
为何呢?下面源代码示意可能会告诉你答案:
body,
html {
height: 100%;
margin: 0;
overflow: hidden;
}
.container {
height: 100%;
overflow: auto; /* 滚动条来自这里 */
}
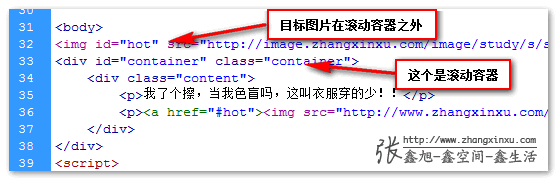
本demo的滚动实际上是由container这个div产生的,而id为hot的这张图片在container之外,因此,锚点定位图片是无法上移的,因为图片父级木有可滚动的容器。
2. 双滚动条定位机制
我们还可能遇到这样的情况,即锚点元素有两个父容器有滚动条,比方说我博客后台页面,滚动条的表哥表姐都出现了: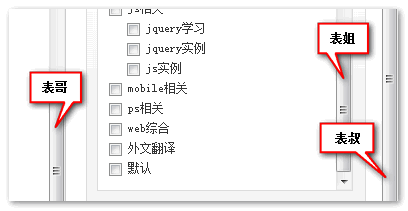
不知有没有想过这个问题,这种情况下,元素锚点定位,是先改变爷爷的滚动高度呢还是爸爸的滚动高度呢?小demo可参见这里。
目前,我还没想出100%证实的实验方法(因为父亲和爷爷的定位是一瞬间完成的,无法通过计算获知),不过,从理解上,个人认为计算是从里面发起的,原因有两个:
首先,如果先计算最外容器,可能就会存在一种里外里3次计算的情况。
//zxx: 下面的研究与探讨多半没有实际价值,实用主义派可以绕开干你的活去。
demo页面的情况,无论内外先计算,都是两次就完成,因为,最后定位的结果是,图片上边缘/内滚动容器上边缘/浏览器可视区域上边缘三者对齐。换成容易理解的解释:柯南,毛利兰,小五郎在死人的时候会聚在一起(锚点定位对齐),假设嫌疑犯A让柯南和毛利兰在一起(内滚动定位),嫌疑犯B可以让毛利兰和小五郎在一起(外滚动定位)。则无论是嫌疑犯B先行动,还是嫌疑犯B先行动,最后都是三者在一起,都是2步完成。
但是,存在这样一种情况,锚点元素在滚动容器的负左上距离处或底部(即无法让元素滚动到顶部),如下截图:
此时,定位的最后结果不是图片上边缘/内滚动容器上边缘/浏览器可视区域上边缘三者对齐了。而是,图片上边缘,内部容器的半部分以及浏览器可视区域上边缘三者对齐。见下: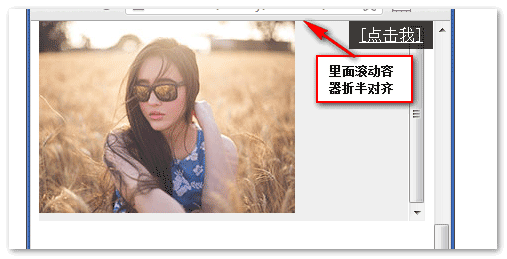
此时,如果外部先计算,则需要3步了——外部滚动条不知道内部滚动应当定位的情况,其只能让内部容器上边缘和浏览器对齐(或干等);内部定位;外部发现位置不是自己所想,再次调整!
显然,这种情况,要先内部可以确定滚动位置的先偏移,然后在父级容器;
再者,我们滚轮鼠标触发滚动的时候,总是里面的先滚,滚不动了才滚外部滚动条;虽然有些牵强,但,隐隐中可以感受到那种由内而外的调调。
再啰嗦点废话,有人可能会疑问,这谁先计算压根就没有研究的意义吧,你研究这个的目的是什么呢?
这个问题乍听上去没什么问题?实际上,多少隐射出中国这个大环境浮躁与功利性的心态。
作为职业人,学习带有功利性其实也没什么不好;商业需要什么,什么学习有商业价值,我去学习之,没什么不好,大家都需要养家糊口的。但是,要是所有人都这个心态,怕不是什么好现象。
我之所以研究“内外滚动谁先计算”,真没什么目的,我就只是好奇,我就是希望得到一个正确的结论。私心肯定有,我希望自己在寻找结论的过程中,获得一些意外的知识与结论,通过深入的思考,走在别人未曾走过的道路上;当然,也希望得到我想要的结论,而不关心是否有价值。即单纯的研究心态。
研究这个东西,本来就不应该为了某个目的而去做,否则就是功利性研究,这就是为何中国科研烂到一坨屎的原因之一。牛顿哥哥被苹果砸,他就是好奇,为何苹果砸我,于是他去研究,你说他研究苹果为何往下掉有什么目的吗?难道要向苹果报仇?在中国,鲜有人会研究苹果为何往下掉,可能会有很多人会研究怎么让苹果长得像西施一样好看——有钱赚啊!
我觉得我们做技术研究,大可鄙弃“研究这个有什么价值”这个功利性的思考,喜欢什么,好奇什么,就去研究什么,价值?目的?等研究结束了,可能会有更深远的价值。
但话说回来,上头拿钱给你,肯定不是想让你搞些无用的研究的。所谓人在江湖漂,哪有不挨刀。每人心中都有自己的一杆秤,该如何做还是自己决定。
3. overflow:hidden下的锚点定位
首先,大家要明确一点,overflow:hidden跟overflow:auto/scroll的差别就在于有没有那个滚动条。元素overflow:hidden了,里面内容高度溢出的时候,滚动依然存在,仅仅滚动条不存在!
下面这种GIF动画演示了锚点元素如何通过滚动高度的改变定位到滚动容器上边缘的;该动画适用于有滚动条以及没有滚动条的情况。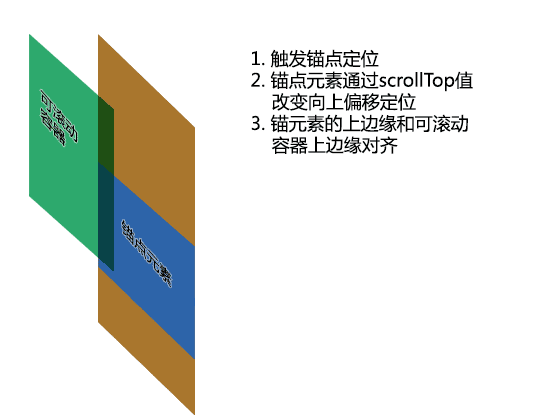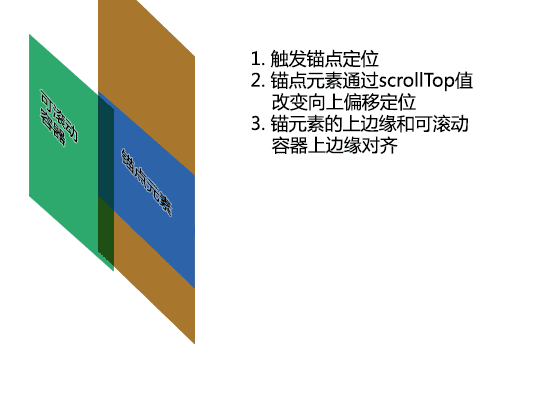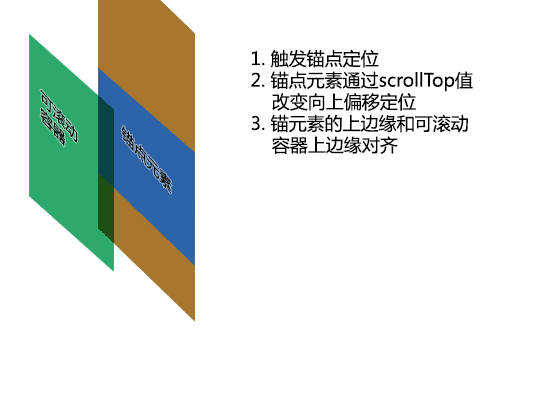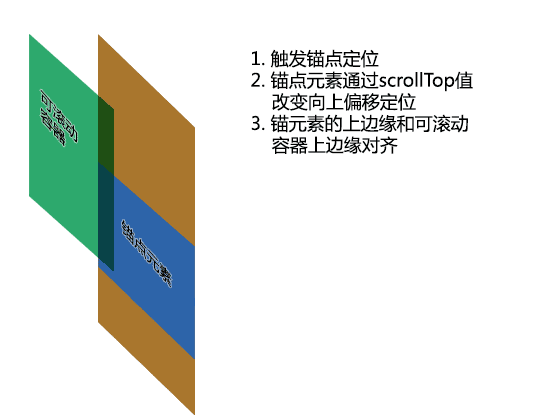
我这里多次强调overflow:hidden没有滚动条这种情况,不是因为今天周五心情好,而是因为一些高级应用以及奇怪问题出现(参见后面)都是在overflow:hidden条件下。
正如上面反复提到,锚点定位本质就是滚传床单。因此,如果元素在滚动容器的左上角区域及其之外,显然滚不动,自然也没有锚点定位的效果!但是,如果元素在滚动容器的右下方及其之外,滚动条就是用来滚动右下溢出内容的,因此,这类元素可以被锚点定位。
以上结论略含糊,后面的例子会让你清楚我在说什么的。
四、锚点定位机制下的应用
锚点定位机制的最经典应用就是“无JavaScript实现选项卡轮转切换效果”。
如果您觉得此页面上看此效果有干扰(锚点跳来跳去,好讨厌哦),可以狠狠地点击这里:无JavaScript实现的切换效果demo
如果您理解上面那句“锚点定位本质就是滚动”的含义,则上面的效果就很好理解了。
点击下面这个按钮,把上面容器从overflow:hidden改成overflow:auto,亲自滚滚床单,您就会知道怎么回事了(参考上面GIF的定位示意图)!
overflow:hidden实际上是个障眼法,里面的选项卡列表们因为锚点定位而一个一个滚动到容器上边缘了,就形成了“选项卡切换”效果。
上面的例子因为是垂直滚动,因此,容器定高了;我们还可以改成水平滚动,让列表们水平排列,也可以实现类似的效果。
同样的,图片列表那种滑来滑去浏览的效果,我们也可以借助锚点;当然,使用锚点是为了让JS挂掉时候依然可用。实际,我们要组织锚点默认的行为的,因为——这种跳来跳去的效果不是平滑滴。//zxx: 据我亲自测试,Chrome实验性质的平滑滚动并不适用于锚点跳转
五、:target伪类与锚点的配合
在CSS2的时代,锚点的应用并不是很广泛,或者说不被看好与关注,很大一部分原因在于没有CSS这个好帮手辅助。CSS3中有个名外:target的伪类选择器,我跟你们讲,这可是个好东西。没有:target锚点就像30年前的甲鱼,送人都没人要;有个:target,锚点的应用开始走上香饽饽之路,潜力与价值立马彰显。如果不是还有半壁的IE6-IE8浏览器,我一定大力推崇:target伪类与锚点技术。
好了,吹嘘的话语讲完了,到底是真是假,举个例子让大家明鉴下。我经常会去中国天气官网看4-7天天气预报(影响我的钓鱼计划),其中有个“查看未来4-7天天气”的按钮(见下图),其href地址是#, 交互式JS实现的,而且JS在底部加载,且该网站加载速度较慢。于是,差不多页面呈现的前半分钟,我点击这个按钮都是徒劳的,反而是出触发了#的返回顶部功能,更多天气不出来——非常糟糕的体验。
其实,要提高体验很简单,JS我们保留,HTML和CSS稍作修改,档次立马不一样!
小二,给我上盘demo过来~
好嘞,客官,您可以狠狠地点击这里::target与锚点元素显示隐藏效果demo
点击demo中“查看4-7天天气”可以浏览展开与收起效果,如下gif动画截图演示:
此效果完全HTML+CSS实现,JS酱油。此方法与“复选框显示隐藏控制法”并称新时代CSS显隐技术两大神器。
:target伪类可以表示URL锚链对应的元素被锚中时候的状态。例如,点击“展开…”按钮后,锚链是"#7d",则此时,就可以激活锚点元素:target选择器,例如:
<div id="7d" class="weatherYubao"></div>
.weatherYubao:target {} /* 我终于执行啦! */
:target伪类的显隐控制比单复选框要灵活很多,因为其可以不仅可以通过兄弟选择器控制样式,还可以使用父子选择器(如本demo),且推荐使用父子选择器可以做更多精确的控制(展开与收起的状态等)。
.weatherYubao:target #weatherYubao2 {
display: block;
}
.weatherYubao:target ...
但是,不足也显而易见,触发定位,即页面的scroll滚动会改变⑤,略影响体验。但,这只是JS尚未载入完毕的交互体验增强之法,实际还是要借助JS组织默认行为的。因此此技术大可使用,因为是纯JS方法上的改进。
//zxx: ⑤ 如果您有锚链改变,但页面不滚动的方法,欢迎分享
:target伪类选择器IE9+, 以及其他现代浏览器支持。但,这并不影响该技术的使用,因为是纯JS方法上的改进。
六、锚点定位机制产生的问题
好的影视作品是要有波澜起伏的,到目前为止,展示的都是锚点定位的正面形象,现在,有必要曝光下锚点定位机制对交互实现造成的影响。
根据上面的介绍,理论上,我们可以借助:target伪类以及CSS3 transition或者animation实现动画效果。
比方说上面的查看4-7天气demo,我们再稍作调整~
小二~
懂的,客官,来了~
客官,您可以狠狠地点击这里::target伪类与锚点元素的动画显隐demo
为展示平滑效果,截了个视频:
变化很简单,display:none/block显隐,改成height值控制的隐藏。
#weatherYubao2 {
height: 0px;
overflow: hidden;
transition: height .35s;
}
.weatherYubao:target #weatherYubao2 {
height: 300px;
}
哟,不错哦。那有什么问题呢?
我想实现上面1,2,3,4选项卡从下往上slide动画效果,可以不?
按照我们常规实现slide向上相关的思路,应该是从translateY(100%)到translateY(0%)的变化,我们来试试~
IE10+以及其他现代浏览器下,您可以狠狠地点击这里:常规slideup思路下demo
但是,demo页面的效果很奇怪,点击那个选项卡,元素上去了,然后就不见了,咋回事?
博主,是你这个demo做的有问题吧!?
非也非也!还是上面那个demo,我们其他什么都不修改,就把从下往上进入的slide动画效果改成从上往下,也就是动画方向从↑改成↓。
IE10+以及其他现代浏览器下,您可以狠狠地点击这里:常规slidedown思路下demo
您会发现:“哟,这里效果挺正常的嘛~~”。
真的就translateY(100%)改成translateY(-100%)这一点点的差异(不信诸位可以右键源代码查看),那为何向上效果嗝屁;而向下效果却是好的呢?
其实我上面已经给了答案了,上面曾说过下面这段话:
如果元素在滚动容器的左上角区域及其之外,显然滚不动,自然也没有锚点定位的效果!但是,如果元素在滚动容器的右下方及其之外,滚动条就是用来滚动右下溢出内容的,因此,这类元素可以被锚点定位。
slidedown效果是元素从容器的上面往下出现,在触发锚点定位的时候,这个元素是没有定位的。但是,slideup是从下面开始,在执行CSS的translateY(100%)的一瞬间,实际上一个等高的滚动条已经出现,锚点定位于是被触发,元素被上移一个身位;然后slideup动画触发,于是,元素跑到了容器之外,不可见了,这就是slideup demo中元素莫名向上的原因。
文字解释苍白,看下面的分解示意图:
如何解决此问题?
很简单,两个字:“延时”!
slideup效果是从translateY(100%)到translateY(0%),其效果不能准确呈现的终极原因就是translateY(100%)造成的滚动和锚点定位偏移滚动同一时间出现造成了冲突!
避免这个问题很简单,我们只要让动画效果,尤其code>translateY(100%)的应用延时,CSS是可以搞定的。
有必要来一发,您可以狠狠地点击这里:延时解决slideup和锚点定位冲突demo
您会惊讶地发现,已经几乎完全真实的slideup效果,之前的选项内容向上隐藏,新点击的内容从下出现显示。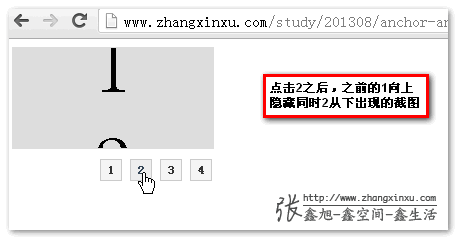
于是,纯CSS实现带slide动画效果的选项卡完美呈现。相关CSS代码如下(省略私有前缀, .05s表延迟时间):
@keyframes slideupin {
0% {transform: translateY(100%); }
100% { transform: translateY(0%);}
}
.list{
... position:absolute;
transform: translateY(-100%);
transition: transform .35s .05s linear;
}
.list:target {
z-index: 1; /* 最上面显示 */
transform: translateY(0%);
animation: slideupin .35s .05s linear forwards;
}
七、未来高端流行技术之一:锚点技术
其实,当下,锚点技术就可以在实际项目中大规模使用了,不过其身份是“CSS效果增强”,即更强的CSS action效果。我们依然保留JS在交互中的主导地位,但是同时完美融合CSS+HTML的锚点技术——JS只要return false或event.preventDefault()组织了默认行为就不要担心CSS会抢占自己的王位。
然,融合与兼顾必然会存在一些细节上的问题。这些问题即使我现在拿出来讲,其实也是秋风扫落叶,无人问津,时机很重要。
我一向推荐看问题要面向未来。虽然说,最为锚点技术最核心的:target伪类目前IE6-IE8浏览器不支持,阻碍了其繁荣昌盛。但是,在不久的将来,或许就1~2年时间,新毕业的小朋友可能就觉得我们这些还拿IE8说事的叔叔阿姨们太凹凸曼了!

举个简单例子。比方说微博这个产品,09年10年出来的,无论是新浪的,还是腾讯的。网页的效果、图形化东西等主要是通过图片增强的,而不是CSS增强;到了当下,视网膜等设备对网页有个更高的要求,图片增强的网页有种鲜花插牛粪的感觉。于是,后面的结果是——专门做一个独立的针对移动设备的版本!
其中要看清两点:
其一,这些公司大,资源丰富,另开个新项目,尤其是网页这个短期项目,肥猪身上割块肉,还是能跑能跳的。但是大多数公司中小企业,加上国家坑爹的政策,这些企业活得很辛苦,资金很紧张。你说web项目还不容器上了一段时间,为了iPad浏览器效果,又专门搞个移动版本,其中的开发、推广等人力成本可想而知,钱就这样被烧掉了。但是,如果从面向未来的角度做产品,比方说技术这一块,以后所节约的成本可能会相当惊人。
其二,这些公司大,但是做事相对不灵活。毕竟用户基数大,一个网站从图片增强改为CSS增强,这个担子谁都担不起。只能做新的版本。但是,中小企业不一样。这些公司产品为了面向未来而作一定的牺牲与舍弃是完全可以,而且应该如此。例如尝试响应式布局、或者大量应用面向未来的一些技术,比如本文展示的锚点技术,在此基础上做JS增强。于是,3年后,到了一个新的设备时代,这个网站尼玛俨然成为流行之先驱了。
学习马云,高瞻远瞩,把握未来。
八、结尾滚床单时间
进入新环境,需要时间适应,例如新的时间规划安排等,技术的学习与博客更新会慢慢进入正常。擦,突然想起来,忘记探讨一个重要的问题了,为何href="#"点击后,触发的效果是回到页面顶部呢?对于这个问题,您怎么看呢?不妨我们一起探讨下(评论、邮件均可)~~
最后再补充两个小tip:
1. F5刷新不会触发锚点定位,在Chrome浏览器下,这个过程由三部曲完成:首先,滚动高度为0;其次,锚点定位高度;最后,还原成刷新之前滚动条的滚动高度。您也可以自己F5试试,会看到滚动条明显的重定位。
2. 连续按F5,或者说长按F5,则似乎等同于Ctrl+F5, Chrome浏览器以及IE浏览器都是如此。
推荐阅读
-
理解URL锚点在HTML中的定位技术原理
-
SSM三大框架基础面试题-一、Spring篇 什么是Spring框架? Spring是一种轻量级框架,提高开发人员的开发效率以及系统的可维护性。 我们一般说的Spring框架就是Spring Framework,它是很多模块的集合,使用这些模块可以很方便地协助我们进行开发。这些模块是核心容器、数据访问/集成、Web、AOP(面向切面编程)、工具、消息和测试模块。比如Core Container中的Core组件是Spring所有组件的核心,Beans组件和Context组件是实现IOC和DI的基础,AOP组件用来实现面向切面编程。 Spring的6个特征: 核心技术:依赖注入(DI),AOP,事件(Events),资源,i18n,验证,数据绑定,类型转换,SpEL。 测试:模拟对象,TestContext框架,Spring MVC测试,WebTestClient。 数据访问:事务,DAO支持,JDBC,ORM,编组XML。 Web支持:Spring MVC和Spring WebFlux Web框架。 集成:远程处理,JMS,JCA,JMX,电子邮件,任务,调度,缓存。 语言:Kotlin,Groovy,动态语言。 列举一些重要的Spring模块? Spring Core:核心,可以说Spring其他所有的功能都依赖于该类库。主要提供IOC和DI功能。 Spring Aspects:该模块为与AspectJ的集成提供支持。 Spring AOP:提供面向切面的编程实现。 Spring JDBC:Java数据库连接。 Spring JMS:Java消息服务。 Spring ORM:用于支持Hibernate等ORM工具。 Spring Web:为创建Web应用程序提供支持。 Spring Test:提供了对JUnit和TestNG测试的支持。 谈谈自己对于Spring IOC和AOP的理解 IOC(Inversion Of Controll,控制反转)是一种设计思想: 在程序中手动创建对象的控制权,交由给Spring框架来管理。IOC在其他语言中也有应用,并非Spring特有。IOC容器实际上就是一个Map(key, value),Map中存放的是各种对象。 将对象之间的相互依赖关系交给IOC容器来管理,并由IOC容器完成对象的注入。这样可以很大程度上简化应用的开发,把应用从复杂的依赖关系中解放出来。IOC容器就像是一个工厂一样,当我们需要创建一个对象的时候,只需要配置好配置文件/注解即可,完全不用考虑对象是如何被创建出来的。在实际项目中一个Service类可能由几百甚至上千个类作为它的底层,假如我们需要实例化这个Service,可能要每次都搞清楚这个Service所有底层类的构造函数,这可能会把人逼疯。如果利用IOC的话,你只需要配置好,然后在需要的地方引用就行了,大大增加了项目的可维护性且降低了开发难度。 Spring中的bean的作用域有哪些? 1.singleton:该bean实例为单例 2.prototype:每次请求都会创建一个新的bean实例(多例)。 3.request:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP request内有效。 4.session:每一次HTTP请求都会产生一个新的bean,该bean仅在当前HTTP session内有效。 5.global-session:全局session作用域,仅仅在基于Portlet的Web应用中才有意义,Spring5中已经没有了。Portlet是能够生成语义代码(例如HTML)片段的小型Java Web插件。它们基于Portlet容器,可以像Servlet一样处理HTTP请求。但是与Servlet不同,每个Portlet都有不同的会话。 Spring中的单例bean的线程安全问题了解吗? 概念用于理解:大部分时候我们并没有在系统中使用多线程,所以很少有人会关注这个问题。单例bean存在线程问题,主要是因为当多个线程操作同一个对象的时候,对这个对象的非静态成员变量的写操作会存在线程安全问题。 有两种常见的解决方案(用于回答的点): 1.在bean对象中尽量避免定义可变的成员变量(不太现实)。 2.在类中定义一个ThreadLocal成员变量,将需要的可变成员变量保存在ThreadLocal(线程本地化对象)中(推荐的一种方式)。 ThreadLocal解决多线程变量共享问题(参考博客):https://segmentfault.com/a/1190000009236777 Spring中Bean的生命周期: 1.Bean容器找到配置文件中Spring Bean的定义。 2.Bean容器利用Java Reflection API创建一个Bean的实例。 3.如果涉及到一些属性值,利用set方法设置一些属性值。 4.如果Bean实现了BeanNameAware接口,调用setBeanName方法,传入Bean的名字。 5.如果Bean实现了BeanClassLoaderAware接口,调用setBeanClassLoader方法,传入ClassLoader对象的实例。 6.如果Bean实现了BeanFactoryAware接口,调用setBeanClassFacotory方法,传入ClassLoader对象的实例。 7.与上面的类似,如果实现了其他*Aware接口,就调用相应的方法。 8.如果有和加载这个Bean的Spring容器相关的BeanPostProcessor对象,执postProcessBeforeInitialization方法。 9.如果Bean实现了InitializingBean接口,执行afeterPropertiesSet方法。 10.如果Bean在配置文件中的定义包含init-method属性,执行指定的方法。 11.如果有和加载这个Bean的Spring容器相关的BeanPostProcess对象,执行postProcessAfterInitialization方法。 12.当要销毁Bean的时候,如果Bean实现了DisposableBean接口,执行destroy方法。 13.当要销毁Bean的时候,如果Bean在配置文件中的定义包含destroy-method属性,执行指定的方法。 Spring框架中用到了哪些设计模式? 1.工厂设计模式:Spring使用工厂模式通过BeanFactory和ApplicationContext创建bean对象。 2.代理设计模式:Spring AOP功能的实现。 3.单例设计模式:Spring中的bean默认都是单例的。 4.模板方法模式:Spring中的jdbcTemplate、hibernateTemplate等以Template结尾的对数据库操作的类,它们就使用到了模板模式。 5.包装器设计模式:我们的项目需要连接多个数据库,而且不同的客户在每次访问中根据需要会去访问不同的数据库。这种模式让我们可以根据客户的需求能够动态切换不同的数据源。 6.观察者模式:Spring事件驱动模型就是观察者模式很经典的一个应用。 7.适配器模式:Spring AOP的增强或通知(Advice)使用到了适配器模式、Spring MVC中也是用到了适配器模式适配Controller。 还有很多。。。。。。。 @Component和@Bean的区别是什么 1.作用对象不同。@Component注解作用于类,而@Bean注解作用于方法。 2.@Component注解通常是通过类路径扫描来自动侦测以及自动装配到Spring容器中(我们可以使用@ComponentScan注解定义要扫描的路径)。@Bean注解通常是在标有该注解的方法中定义产生这个bean,告诉Spring这是某个类的实例,当我需要用它的时候还给我。 3.@Bean注解比@Component注解的自定义性更强,而且很多地方只能通过@Bean注解来注册bean。比如当引用第三方库的类需要装配到Spring容器的时候,就只能通过@Bean注解来实现。 @Configuration public class AppConfig { @Bean public TransferService transferService { return new TransferServiceImpl; } } <beans> <bean id="transferService" class="com.kk.TransferServiceImpl"/> </beans> @Bean public OneService getService(status) { case (status) { when 1: return new serviceImpl1; when 2: return new serviceImpl2; when 3: return new serviceImpl3; } } 将一个类声明为Spring的bean的注解有哪些? 声明bean的注解: @Component 组件,没有明确的角色 @Service 在业务逻辑层使用(service层) @Repository 在数据访问层使用(dao层) @Controller 在展现层使用,控制器的声明 注入bean的注解: @Autowired:由Spring提供 @Inject:由JSR-330提供 @Resource:由JSR-250提供 *扩:JSR 是 java 规范标准 Spring事务管理的方式有几种? 1.编程式事务:在代码中硬编码(不推荐使用)。 2.声明式事务:在配置文件中配置(推荐使用),分为基于XML的声明式事务和基于注解的声明式事务。 Spring事务中的隔离级别有哪几种? 在TransactionDefinition接口中定义了五个表示隔离级别的常量:ISOLATION_DEFAULT:使用后端数据库默认的隔离级别,Mysql默认采用的REPEATABLE_READ隔离级别;Oracle默认采用的READ_COMMITTED隔离级别。ISOLATION_READ_UNCOMMITTED:最低的隔离级别,允许读取尚未提交的数据变更,可能会导致脏读、幻读或不可重复读。ISOLATION_READ_COMMITTED:允许读取并发事务已经提交的数据,可以阻止脏读,但是幻读或不可重复读仍有可能发生ISOLATION_REPEATABLE_READ:对同一字段的多次读取结果都是一致的,除非数据是被本身事务自己所修改,可以阻止脏读和不可重复读,但幻读仍有可能发生。ISOLATION_SERIALIZABLE:最高的隔离级别,完全服从ACID的隔离级别。所有的事务依次逐个执行,这样事务之间就完全不可能产生干扰,也就是说,该级别可以防止脏读、不可重复读以及幻读。但是这将严重影响程序的性能。通常情况下也不会用到该级别。 Spring事务中有哪几种事务传播行为? 在TransactionDefinition接口中定义了八个表示事务传播行为的常量。 支持当前事务的情况:PROPAGATION_REQUIRED:如果当前存在事务,则加入该事务;如果当前没有事务,则创建一个新的事务。PROPAGATION_SUPPORTS: 如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务的方式继续运行。PROPAGATION_MANDATORY: 如果当前存在事务,则加入该事务;如果当前没有事务,则抛出异常。(mandatory:强制性)。 不支持当前事务的情况:PROPAGATION_REQUIRES_NEW: 创建一个新的事务,如果当前存在事务,则把当前事务挂起。PROPAGATION_NOT_SUPPORTED: 以非事务方式运行,如果当前存在事务,则把当前事务挂起。PROPAGATION_NEVER: 以非事务方式运行,如果当前存在事务,则抛出异常。 其他情况:PROPAGATION_NESTED: 如果当前存在事务,则创建一个事务作为当前事务的嵌套事务来运行;如果当前没有事务,则该取值等价于PROPAGATION_REQUIRED。 二、SpringMVC篇 什么是Spring MVC ?简单介绍下你对springMVC的理解? Spring MVC是一个基于Java的实现了MVC设计模式的请求驱动类型的轻量级Web框架,通过把Model,View,Controller分离,将web层进行职责解耦,把复杂的web应用分成逻辑清晰的几部分,简化开发,减少出错,方便组内开发人员之间的配合。 Spring MVC的工作原理了解嘛? image.png Springmvc的优点: (1)可以支持各种视图技术,而不仅仅局限于JSP; (2)与Spring框架集成(如IoC容器、AOP等); (3)清晰的角色分配:前端控制器(dispatcherServlet) , 请求到处理器映射(handlerMapping), 处理器适配器(HandlerAdapter), 视图解析器(ViewResolver)。 (4) 支持各种请求资源的映射策略。 Spring MVC的主要组件? (1)前端控制器 DispatcherServlet(不需要程序员开发) 作用:接收请求、响应结果,相当于转发器,有了DispatcherServlet 就减少了其它组件之间的耦合度。 (2)处理器映射器HandlerMapping(不需要程序员开发) 作用:根据请求的URL来查找Handler (3)处理器适配器HandlerAdapter 注意:在编写Handler的时候要按照HandlerAdapter要求的规则去编写,这样适配器HandlerAdapter才可以正确的去执行Handler。 (4)处理器Handler(需要程序员开发) (5)视图解析器 ViewResolver(不需要程序员开发) 作用:进行视图的解析,根据视图逻辑名解析成真正的视图(view) (6)视图View(需要程序员开发jsp) View是一个接口, 它的实现类支持不同的视图类型(jsp,freemarker,pdf等等) springMVC和struts2的区别有哪些? (1)springmvc的入口是一个servlet即前端控制器(DispatchServlet),而struts2入口是一个filter过虑器(StrutsPrepareAndExecuteFilter)。 (2)springmvc是基于方法开发(一个url对应一个方法),请求参数传递到方法的形参,可以设计为单例或多例(建议单例),struts2是基于类开发,传递参数是通过类的属性,只能设计为多例。 (3)Struts采用值栈存储请求和响应的数据,通过OGNL存取数据,springmvc通过参数解析器是将request请求内容解析,并给方法形参赋值,将数据和视图封装成ModelAndView对象,最后又将ModelAndView中的模型数据通过reques域传输到页面。Jsp视图解析器默认使用jstl。 SpringMVC怎么样设定重定向和转发的? (1)转发:在返回值前面加"forward:",譬如"forward:user.do?name=method4" (2)重定向:在返回值前面加"redirect:",譬如"redirect:http://www.baidu.com" SpringMvc怎么和AJAX相互调用的? 通过Jackson框架就可以把Java里面的对象直接转化成Js可以识别的Json对象。具体步骤如下 : (1)加入Jackson.jar (2)在配置文件中配置json的映射 (3)在接受Ajax方法里面可以直接返回Object,List等,但方法前面要加上@ResponseBody注解。 如何解决POST请求中文乱码问题,GET的又如何处理呢? (1)解决post请求乱码问题: 在web.xml中配置一个CharacterEncodingFilter过滤器,设置成utf-8; <filter> <filter-name>CharacterEncodingFilter</filter-name> <filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class> <init-param> <param-name>encoding</param-name> <param-value>utf-8</param-value> </init-param> </filter> <filter-mapping> <filter-name>CharacterEncodingFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping> (2)get请求中文参数出现乱码解决方法有两个: ①修改tomcat配置文件添加编码与工程编码一致,如下: <ConnectorURIEncoding="utf-8" connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/> ②另外一种方法对参数进行重新编码: String userName = new String(request.getParamter("userName").getBytes("ISO8859-1"),"utf-8") ISO8859-1是tomcat默认编码,需要将tomcat编码后的内容按utf-8编码。 Spring MVC的异常处理 ? 统一异常处理: Spring MVC处理异常有3种方式: (1)使用Spring MVC提供的简单异常处理器SimpleMappingExceptionResolver; (2)实现Spring的异常处理接口HandlerExceptionResolver 自定义自己的异常处理器; (3)使用@ExceptionHandler注解实现异常处理; 统一异常处理的博客:https://blog.csdn.net/ctwy291314/article/details/81983103 SpringMVC的控制器是不是单例模式,如果是,有什么问题,怎么解决? 是单例模式,所以在多线程访问的时候有线程安全问题,不要用同步,会影响性能的,解决方案是在控制器里面不能写成员变量。(此题目类似于上面Spring 中 第5题 有两种解决方案) SpringMVC常用的注解有哪些? @RequestMapping:用于处理请求 url 映射的注解,可用于类或方法上。用于类上,则表示类中的所有响应请求的方法都是以该地址作为父路径。 @RequestBody:注解实现接收http请求的json数据,将json转换为java对象。 @ResponseBody:注解实现将conreoller方法返回对象转化为json对象响应给客户。 SpingMvc中的控制器的注解一般用那个,有没有别的注解可以替代? 一般用@Controller注解,也可以使用@RestController,@RestController注解相当于@ResponseBody + @Controller,表示是表现层,除此之外,一般不用别的注解代替。 如果在拦截请求中,我想拦截get方式提交的方法,怎么配置? 可以在@RequestMapping注解里面加上method=RequestMethod.GET。 怎样在方法里面得到Request,或者Session? 直接在方法的形参中声明request,SpringMVC就自动把request对象传入。 如果想在拦截的方法里面得到从前台传入的参数,怎么得到? 直接在形参里面声明这个参数就可以,但必须名字和传过来的参数一样。 如果前台有很多个参数传入,并且这些参数都是一个对象的,那么怎么样快速得到这个对象? 直接在方法中声明这个对象,SpringMVC就自动会把属性赋值到这个对象里面。 SpringMVC中函数的返回值是什么? 返回值可以有很多类型,有String, ModelAndView。ModelAndView类把视图和数据都合并的一起的。 SpringMVC用什么对象从后台向前台传递数据的? 通过ModelMap对象,可以在这个对象里面调用put方法,把对象加到里面,前台就可以拿到数据。 怎么样把ModelMap里面的数据放入Session里面? 可以在类上面加上@SessionAttributes注解,里面包含的字符串就是要放入session里面的key。 SpringMvc里面拦截器是怎么写的: 有两种写法,一种是实现HandlerInterceptor接口,另外一种是继承适配器类,接着在接口方法当中,实现处理逻辑;然后在SpringMvc的配置文件中配置拦截器即可: <!-- 配置SpringMvc的拦截器 --> <mvc:interceptors> <!-- 配置一个拦截器的Bean就可以了 默认是对所有请求都拦截 --> <bean id="myInterceptor" class="com.zwp.action.MyHandlerInterceptor"></bean> <!-- 只针对部分请求拦截 --> <mvc:interceptor> <mvc:mapping path="/modelMap.do" /> <bean class="com.zwp.action.MyHandlerInterceptorAdapter" /> </mvc:interceptor> </mvc:interceptors> 注解原理: 注解本质是一个继承了Annotation的特殊接口,其具体实现类是Java运行时生成的动态代理类。我们通过反射获取注解时,返回的是Java运行时生成的动态代理对象。通过代理对象调用自定义注解的方法,会最终调用AnnotationInvocationHandler的invoke方法。该方法会从memberValues这个Map中索引出对应的值。而memberValues的来源是Java常量池 三、Mybatis篇 什么是MyBatis? MyBatis是一个可以自定义SQL、存储过程和高级映射的持久层框架。 讲下MyBatis的缓存 MyBatis的缓存分为一级缓存和二级缓存,一级缓存放在session里面,默认就有, 二级缓存放在它的命名空间里,默认是不打开的,使用二级缓存属性类需要实现Serializable序列化接口, 可在它的映射文件中配置<cache/> Mybatis是如何进行分页的?分页插件的原理是什么? 1)Mybatis使用RowBounds对象进行分页,也可以直接编写sql实现分页,也可以使用Mybatis的分页插件。 2)分页插件的原理:实现Mybatis提供的接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql。 举例:select * from student,拦截sql后重写为:select t.* from (select * from student)t limit 0,10 简述Mybatis的插件运行原理,以及如何编写一个插件? 1)Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、 Executor这4种接口的插件,Mybatis通过动态代理, 为需要拦截的接口生成代理对象以实现接口方法拦截功能, 每当执行这4种接口对象的方法时,就会进入拦截方法, 具体就是InvocationHandler的invoke方法,当然, 只会拦截那些你指定需要拦截的方法。 2)实现Mybatis的Interceptor接口并复写intercept方法, 然后在给插件编写注解,指定要拦截哪一个接口的哪些方法即可, 记住,别忘了在配置文件中配置你编写的插件。 Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不? 1)Mybatis动态sql可以让我们在Xml映射文件内, 以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能。 2)Mybatis提供了9种动态sql标签:trim|where|set|foreach|if|choose|when|otherwise|bind。 3)其执行原理为,使用OGNL从sql参数对象中计算表达式的值, 根据表达式的值动态拼接sql,以此来完成动态sql的功能。 #{}和${}的区别是什么? 1)#{}是预编译处理,${}是字符串替换。 2)Mybatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值(有效的防止SQL注入); 3)Mybatis在处理${}时,就是把${}替换成变量的值。 为什么说Mybatis是半自动ORM映射工具?它与全自动的区别在哪里? Hibernate属于全自动ORM映射工具, 使用Hibernate查询关联对象或者关联集合对象时, 可以根据对象关系模型直接获取,所以它是全自动的。 而Mybatis在查询关联对象或关联集合对象时, 需要手动编写sql来完成,所以,称之为半自动ORM映射工具。 Mybatis是否支持延迟加载?如果支持,它的实现原理是什么? 1)Mybatis仅支持association关联对象和collection关联集合对象的延迟加载, association指的就是一对一,collection指的就是一对多查询。 在Mybatis配置文件中, 可以配置是否启用延迟加载lazyLoadingEnabled=true|false。 2)它的原理是,使用CGLIB创建目标对象的代理对象, 当调用目标方法时,进入拦截器方法, 比如调用a.getB.getName, 拦截器invoke方法发现a.getB是null值, 那么就会单独发送事先保存好的查询关联B对象的sql, 把B查询上来,然后调用a.setB(b), 于是a的对象b属性就有值了, 接着完成a.getB.getName方法的调用。 这就是延迟加载的基本原理。 MyBatis与Hibernate有哪些不同? 1)Mybatis和hibernate不同,它不完全是一个ORM框架, 因为MyBatis需要程序员自己编写Sql语句, 不过mybatis可以通过XML或注解方式灵活配置要运行的sql语句, 并将java对象和sql语句映射生成最终执行的sql, 最后将sql执行的结果再映射生成java对象。 2)Mybatis学习门槛低,简单易学,程序员直接编写原生态sql, 可严格控制sql执行性能,灵活度高,非常适合对关系数据模型要求不高的软件开发, 例如互联网软件、企业运营类软件等,因为这类软件需求变化频繁, 一但需求变化要求成果输出迅速。但是灵活的前提是mybatis无法做到数据库无关性, 如果需要实现支持多种数据库的软件则需要自定义多套sql映射文件,工作量大。 3)Hibernate对象/关系映射能力强,数据库无关性好, 对于关系模型要求高的软件(例如需求固定的定制化软件) 如果用hibernate开发可以节省很多代码,提高效率。 但是Hibernate的缺点是学习门槛高,要精通门槛更高, 而且怎么设计O/R映射,在性能和对象模型之间如何权衡, 以及怎样用好Hibernate需要具有很强的经验和能力才行。 总之,按照用户的需求在有限的资源环境下只要能做出维护性、 扩展性良好的软件架构都是好架构,所以框架只有适合才是最好。 MyBatis的好处是什么? 1)MyBatis把sql语句从Java源程序中独立出来,放在单独的XML文件中编写, 给程序的维护带来了很大便利。 2)MyBatis封装了底层JDBC API的调用细节,并能自动将结果集转换成Java Bean对象, 大大简化了Java数据库编程的重复工作。 3)因为MyBatis需要程序员自己去编写sql语句, 程序员可以结合数据库自身的特点灵活控制sql语句, 因此能够实现比Hibernate等全自动orm框架更高的查询效率,能够完成复杂查询。 简述Mybatis的Xml映射文件和Mybatis内部数据结构之间的映射关系? Mybatis将所有Xml配置信息都封装到All-In-One重量级对象Configuration内部。 在Xml映射文件中,<parameterMap>标签会被解析为ParameterMap对象, 其每个子元素会被解析为ParameterMapping对象。 <resultMap>标签会被解析为ResultMap对象, 其每个子元素会被解析为ResultMapping对象。 每一个<select>、<insert>、<update>、<delete> 标签均会被解析为MappedStatement对象, 标签内的sql会被解析为BoundSql对象。 什么是MyBatis的接口绑定,有什么好处? 接口映射就是在MyBatis中任意定义接口,然后把接口里面的方法和SQL语句绑定, 我们直接调用接口方法就可以,这样比起原来了SqlSession提供的方法我们可以有更加灵活的选择和设置. 接口绑定有几种实现方式,分别是怎么实现的? 接口绑定有两种实现方式,一种是通过注解绑定,就是在接口的方法上面加 上@Select@Update等注解里面包含Sql语句来绑定, 另外一种就是通过xml里面写SQL来绑定,在这种情况下, 要指定xml映射文件里面的namespace必须为接口的全路径名. 什么情况下用注解绑定,什么情况下用xml绑定? 当Sql语句比较简单时候,用注解绑定;当SQL语句比较复杂时候,用xml绑定,一般用xml绑定的比较多 MyBatis实现一对一有几种方式?具体怎么操作的? 有联合查询和嵌套查询,联合查询是几个表联合查询,只查询一次, 通过在resultMap里面配置association节点配置一对一的类就可以完成; 嵌套查询是先查一个表,根据这个表里面的结果的外键id, 去再另外一个表里面查询数据,也是通过association配置, 但另外一个表的查询通过select属性配置。 Mybatis能执行一对一、一对多的关联查询吗?都有哪些实现方式,以及它们之间的区别? 能,Mybatis不仅可以执行一对一、一对多的关联查询, 还可以执行多对一,多对多的关联查询,多对一查询, 其实就是一对一查询,只需要把selectOne修改为selectList即可; 多对多查询,其实就是一对多查询,只需要把selectOne修改为selectList即可。 关联对象查询,有两种实现方式,一种是单独发送一个sql去查询关联对象, 赋给主对象,然后返回主对象。另一种是使用嵌套查询,嵌套查询的含义为使用join查询, 一部分列是A对象的属性值,另外一部分列是关联对象B的属性值, 好处是只发一个sql查询,就可以把主对象和其关联对象查出来。 MyBatis里面的动态Sql是怎么设定的?用什么语法? MyBatis里面的动态Sql一般是通过if节点来实现,通过OGNL语法来实现, 但是如果要写的完整,必须配合where,trim节点,where节点是判断包含节点有 内容就插入where,否则不插入,trim节点是用来判断如果动态语句是以and 或or 开始,那么会自动把这个and或者or取掉。 Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式? 第一种是使用<resultMap>标签,逐一定义列名和对象属性名之间的映射关系。 第二种是使用sql列的别名功能,将列别名书写为对象属性名, 比如T_NAME AS NAME,对象属性名一般是name,小写, 但是列名不区分大小写,Mybatis会忽略列名大小写,